



Si scrive AlphaZero e da oggi cambia tutto




Il blog Uno Scacchista ha pubblicato un articolo sulla netta vittoria di AlphaZero su Stockfish, notizia che ha sbalordito gran parte degli osservatori di cose scacchistiche. Ritenendo l’articolo molto interessante, la Redazione ha deciso di pubblicarlo integralmente anche su Scacchierando e ringrazia Uberto Delprato (autore del Blog) per l’autorizzazione concessa.
Il 5 Dicembre 2017 sarà un giorno da ricordare. Se non entrerà nella storia è solo perchè altre date più simboliche seguiranno presto, ma per gli scacchi oggi cambia tutto. Non perchè un computer abbia superato in forza scacchistica i giocatori umani, quello è successo da tempo, ma perchè un programma non specializzato per giocare a scacchi ha battuto uno dei programmi scacchistici più forti dopo solo quattro ore di autoapprendimento.
Sbalorditi? Cominciamo da fatti e antefatti.
E’ notizia recente (Maggio di quest’anno) che il numero 1 della classifica mondiale dei giocatori professionisti di Go, è stato battuto, per la prima volta nella storia, in un match contro un programma. Il fatto ha destato molto scalpore perchè il Go è considerato il gioco strategicamente più complesso e difficile da giocare per i programmi. Eppure AlphaGo, un programma sviluppato dalla società DeepMind di Londra (una società di Google), lo ha fatto in maniera convincente.

Il n.1 del Go mondiale, Ke Jie, durante la sfida con AlphaGo
Nella risonanza della notizia, solo in pochi hanno compreso cosa c’era veramente dietro al risultato: AlphaGo, al contrario della totalità dei programmi prima di lui, non ha utilizzato un metodo di analisi basato sulla cosiddetta “forza bruta” (ovvero sul calcolo esaustivo di tutte le possibili sequenze) nè su un algoritmo di ricerca “alpha-beta” calibrato con parametri di valutazione suggerito da giocatori umani. Tanto per capirci, il primo metodo è stato il primo ad essere abbandonato anche nel caso degli scacchi, perchè di applicabilità pratica nulla: se funzionasse, il gioco in esame sarebbe risolto completamente, come nel caso del semplice gioco “Tris”. E’ però usato (anche se in analisi retrograda) per la costruzione delle cosiddette “Tablebase”, ovvero dei database che risolvono completamente i finali di scacchi fino un massimo di 7 pezzi sulla scacchiera.

Tutti gli attuali programmi di scacchi usano invece un metodo basato sulla valutazione delle posizioni sulla base di algoritmi, sempre più sofisticati, che vengono personalizzati dai programmatori in funzione sia della loro abilità (ci sono sempre Grandi Maestri nei team di sviluppo) sia della “personalità” che si vuol dare al programma. La capacità di un programma si misura anche nella capacità di cambiare “mappatura” dei parametri di decisione “Alpha-Beta” a seconda della fase di gioco e della dinamicità della posizione.
Bene tutto questo non stava funzionando per il Go e i ricercatori di DeepMind hanno pensato di applicare un metodo completamente diverso: realizzare e istruire una rete neurale che sapesse giocare a Go. Senza entrare nel dettaglio di un concetto già applicato in altri campi da decenni, significa creare un numero molto alto di semplici nodi (neuroni) collegati in una fitta rete, che prendono singolarmente una decisione binaria (si/no, ovvero vero/falso) basandosi solamente sui valori dei suoi nodi predecessori e di alcuni “pesi” che vengono definiti autonomamente dalla rete stessa durante la fase di apprendimento (mi scuseranno gli esperti per questa voluta semplificazione). Il risultati di tutti i livelli di elaborazione è una decisione finale della rete (ovvero, nel nostro caso, la mossa da eseguire sulla scacchiera).
Il tutto ricorda la struttura del nostro cervello (molti neuroni collegati in rete), che riesce ad apprendere, ovvero a prendere decisioni basate sull’esperienza, una volta che sia riuscito a raccogliere sufficienti informazioni sulle conseguenze di una decisione. Questo hanno immaginato di fare i programmatori di AlphaGo: creare una rete neurale che, opportunamente istruita e in grado di affinarsi con l’aumentare delle partite analizzate, sarebbe stata in grado di scegliere una mossa non sulla base di un calcolo, ma sulla base della esperienza pratica. E il metodo, che in passato era stato già tentato con scarsi risultati probabilmente a causa delle minori capacità computazionali, ha avuto successo, come abbiamo visto.
E, altra cosa interessantissima, la rete è stata progettata per non avere bisogno di analizzare un numero elevato di decisioni possibili, ma, nel caso di AlphaGo, lo ha fatto utlizzando un algoritmo chiamato “MonteCarlo”, che (come il nome suggerisce) è completamente casuale ma corretto da un “pizzico” di calcolo delle probabilità. Insomma la rete “esplora” le possibili alternative con un certo margine di casualità, garantendo una copertura vasta dell’universo delle varianti.
Dopo aver vinto con AlphaGo, i ricercatori di DeepMind avevano annunciato che non si sarebbero fermati e avrebbero cercato di espandere le capacità del programma, affrontando anche altri giochi.
Ed eccoci arrivati a quello che è stato comunicato nel documento pubblicato il 5 Dicembre: Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm.

L’evoluzione di AlphaGo, chiamata AlphaZero, è stata progettata e realizzata per poter giocare a Scacchi, Shogi e Go a partire da zero (“tabula rasa“), ovvero conoscendo solamente le regole dei giochi.
Ebbene, nel caso degli scacchi, AlphaZero ha imparato giocando 700.000 partite contro se stesso. Tutto qua. Durante l’apprendimento, il programma è stato fatto giocare contro Stockfish in modo da valutarne la forza relativa.
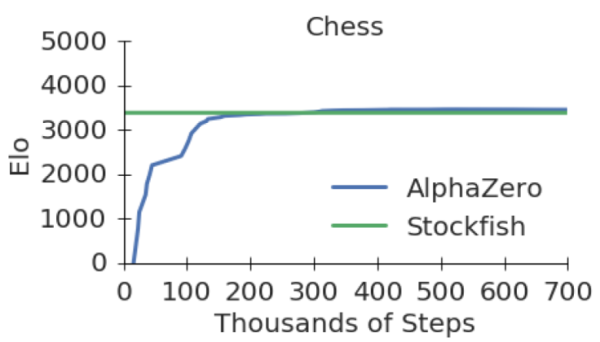
Dopo solo 4 ore di apprendimento (avete letto bene – quattro ore), AlphaZero aveva raggiunto la forza di Stockfish (attorno ai 3300 Elo), per poi superarlo. In un match su 100 partite, non c’è stata storia: AlphaZero ha vinto 28 a 0, con 72 patte

Possiamo guardare questo risultato (e quelli, analoghi, per lo Shogi e il Go) con sbalordimento, ma il 5 Dicembre ci è stato ufficialmente detto e dimostrato dai ricercatori della DeepMind che:
- è possibile realizzare un programma per computer in grado di imparare a prendere sequenze di decisioni che si sono dimostrate superiori a quelle degli uomini e di altri programmi nel caso di tre giochi di strategia ritenuti rappresentativi di una classe complessa di problemi
- il sistema di auto-apprendimento e di valutazione dei risultati può essere molto rapido
- l’applicazione del metodo MonteCarlo alle reti neurali ha come risultato un algoritmo decisionale molto efficace (come provato dal fatto che AlphaZero analizza 80.000 posizioni al secondo nel caso degli scacchi, mentre Stockfish ne analizza 70 milioni al secondo)
Se ne avete tempo e voglia potete leggere l’articolo (in inglese) per maggiori dettagli, ma l’impressione che ho avuto leggendo la pubblicazione è la stessa che provai quando lessi per la prima volta dei lavori di Turing. Egli compì l’incredibile (all’epoca) passo di rendere una macchina programmabile, ovvero in grado di svolgere diversi compiti (anche giocare a scacchi) rimanendo se stessa, eseguendo istruzioni diverse definite dal suo programmatore. Qui stiamo parlando di una macchina (di tipo informatico) che è in grado di imparare da sola come svolgere benissimo un certo task del quale a priori conosce solamente le regole generali; una macchina che è in grado di apprendere senza neanche bisogno di avere un insegnante, ma solamente dall’esperienza pratica. Non è che questo viene scoperto oggi: è che oggi lo vedo per la prima volta applicato agli scacchi, un gioco che mai avrei potuto immaginare si potesse apprendere e giocare a livelli altissimi, senza un lungo percorso di istruzione.

![]()
Ma anche guardando il risultato puramente scacchistico, dobbiamo notare, sbigottiti, che:
- il metodo di apprendimento di AlphaZero non è mai stato sperimentato (immaginate un singolo uomo che debba studiare gli scacchi giocando unicamente contro se stesso), ma il risultato è spettacolare;
- un programma che ha analizzato il gioco “da zero”, quindi senza preconcetti o i risultati di analisi precedenti, ha “riscoperto” la teoria delle aperture arrivando a conclusioni molto simili a quelle a cui noi umani siamo arrivati dopo secoli di studio;
- la qualità del gioco di AlphaZero è davvero eccellente: nell’articolo pubblicato sono incluse 10 partite del match con Stockfish e c’è da rimanere a bocca aperta di fronte alla fantasia tattica e alla profondità strategica del programma.
- l’approccio alla partita è stranamente molto “umano”, con molta fantasia nell’identificare le continuazioni più tattiche
Le reazioni della comunità scacchistica sono quasi tutte improntate alla dichiarazione di “fine” degli scacchi. Personalmente non lo condivido: è ormai da tempo che i computer sono più forti degli uomini e sicuramente AlphaZero sarà in grado di esplorare nuove possibilità del gioco. E’ però vero che quando questo programma o uno simile sarà messo a disposizione dei Grandi Maestri, sempre più ci sarà il rischio di vedere i giocatori ridotti a esecutori di sequenze mandate a memoria. Diciamo che, dopo l’avvento dei programmi scacchistici, questa è una nuova svolta che può mettere fine agli scacchi “per come li conosciamo oggi”.
Insomma l’intelligenza potrebbe diventare quella del computer e la pura esecuzione delle mosse essere affidata a umani debitamente istruiti: un ribaltamento completo dei ruoli. Che per fortuna non toccherà il 99.99% degli appassionati di scacchi che continueranno a divertirsi così come ci divertiamo a organizzare gare di atletica che i robot vincerebbero sicuramente.
Rimane per me, in realtà, quel vago timore che ho sempre paventato: che le macchine comincino ad imparare come si fa ad imparare. Una volta fatto questo, come le potremo limitare o controllare? Anche volendole considerare come alleate nelle sfide di tutti i giorni, come evitare che, a forza di imparare, non comincino a considerarci per quello che, ai loro occhi, inevitabilmente sembreremo: esseri a loro inferiori.
Asimov ha scritto bellissimi racconti giocando su questi temi: io spero di avervi dato informazioni e spunti di riflessione. Ripeto l’invito dell’inizio di questo post: segnatevi il 5 Dicembre 2017 sul calendario, perchè a partire da lì qualcosa di inarrestabile è iniziato e ha dimostrato clamorosamente le sue potenzialità.
12 dicembre 2017 - 09:08
I, robot…
0 – Un robot non può recare danno all’umanità, né può permettere che, a causa del proprio mancato intervento, l’umanità riceva danno.
1 – Un robot non può recar danno a un essere umano né può permettere che, a causa del proprio mancato intervento, un essere umano riceva danno. Purché questo non contrasti con la Legge Zero
2 – Un robot deve obbedire agli ordini impartiti dagli esseri umani, purché tali ordini non contravvengano alla Legge Zero e alla Prima Legge.
3 – Un robot deve proteggere la propria esistenza, purché questa autodifesa non contrasti con la Legge Zero, la Prima Legge e la Seconda Legge.
Ma Asimov era un grande ottimista… 🙂
12 dicembre 2017 - 10:57
Uhm. Interessante, ma… “c’è qualquadra che non cosa”.
Mi mancano parecchi elementi *fondamentali* per capire come realmente è andato il match con stockfish: tempi di riflessione? Hardware? Libro di aperture per Stockfish? Uso tablebase?
E comunque, se si tratta di “Banale” analisi MonteCarlo, non è nulla di nuovo, solo che evidentemente hanno trovato un modo di farla fare in maniera “economica” sulla potenza di calcolo e i tempi
12 dicembre 2017 - 12:14
Non sono convinto, per i motivi già accennati da Lordste, e anche per un sano principio di precauzione che guida (quasi) sempre le mie scelte.
Per essere valido un esperimento deve essere riproducibile e quindi tutti gli elementi devono essere noti, anche i dettagli apparentemente secondari.
La analisi Montecarlo è usata in molti processi per sfoltire calcoli che altrimenti richiederebbero tempi paragonabili al dimezzamento del carbonio 14, però ha limitazioni e controindicazioni che, forse, chi ha impostato questo progetto è riuscito……ehm, diciamo così, a “scavalcare”.
Attendo di essere meglio informato sui dettagli al contorno, prima di esprimere un commento più serio.
12 dicembre 2017 - 12:52
Per chi vuole approfondire consiglio questo articolo su Chess.com, con particolari sul match e reazioni dei top players
https://www.chess.com/news/view/alphazero-reactions-from-top-gms-stockfish-author
Penso che se ci saranno cambiamenti (anche in campi non scacchistici), questi avverrano quando questa tecnologia diventerà accessibile, come è gia accaduto in passato: quando Deep Blue battè Kasparov la notizia fece il giro del mondo, ma ciò influì sugli scacchi giocati e seguiti solo dopo che ci fu la possibilità di avere i software da 3000 ELO sul proprio home computer.
12 dicembre 2017 - 14:14
e soprattutto:
1) è stato fornita prova (e se sì, quale?) che AlphaZero abbia impiegato solo 4 ore per raggiungere quel livello di gioco? a quanto mi pare di capire sono informazioni fornite dagli stessi programmatori di Google, quindi tutte da verificare.
2) per quanto riguarda la sfida con Stoccafisso, beh, a voler essere precisi così come il team di AlphaZero ha stabilito le condizioni a cui ha operato AZ nella sfida, così – di correttezza – si sarebbe dovuta lasciare ai programmatori di Stoccafisso la possibilità di presentarsi con il proprio armamentario hard-software. ma, nella fattispecie, hanno fatto tutto quelli di Google; chi ci assicura che abbiano posto Stoccafisso nelle condizioni ideali di operare?
3) sarà un caso, ma in molte partite giocate tra le due AI, Stoccafisso 8 (questa la versione che il team di Google ha dichiarato di utilizzare) ha effettuato delle scelte – il più delle volte quelle che hanno dato il là alla sconfitta – che nemmeno la versione che possiedo io, la 5, che opera sul miserrimo processore del mio portatile, contemplava.
12 dicembre 2017 - 14:40
Come ho già scritto in altro sito… a AlphaZero è stato data una Ducati da MotoGP (e 4 ore – forse – per imparare a guidarla) mentre a Stockfish è stato dato un “Ciao”, poi li hanno fatti gareggiare…
13 dicembre 2017 - 00:35
ahaha
12 dicembre 2017 - 15:20
Abbastanza pacifico, mia modesta opinione, che le condizioni di gioco (cadenza secca, niente libro aperture, niente tablebase, etc) non fosse esattamente la migliore per far risaltare Stock. E abbastanza pacifico che AlphaZero non sia così più forte del CdMdM*. Ma qui credo il punto sia un altro: qui c’è una macchina che impara dall’esperienza. Un computer scacchistico “farà del suo meglio” con quanto gli abbiamo dato a disposizione e poi sceglierà sempre la stessa mossa, eventuale sconfitta dopo eventuale sconfitta.
“Questo coso” impara partendo da “queste sono le regole” e basta. Lo fa a scacchi come a Go come a shogi. È, mi pare, un qualcosa po’ più grossa di una “montecarlo pompata”. Insomma, do ragione ad Aronian (“I am very excited but I am not sure about the conditions.”) ma credo sia in effetti qualcosa di grosso. 🙂
Che poi il Sig.Google sappia “anche” vendere, sono d’accordo.
*Campione del Mondo delle Macchine
12 dicembre 2017 - 15:24
“Un computer scacchistico “farà del suo meglio” con quanto gli abbiamo dato a disposizione e poi sceglierà sempre la stessa mossa, eventuale sconfitta dopo eventuale sconfitta.”
Hai centrato il punto!
12 dicembre 2017 - 21:04
Sono ancor meno convinto.
Anche le macchine meno sofisticate possono “imparare” dalle esperienze fatte, basta registrare le mosse fatte e correlarle ai risultati conseguiti, che poi vanno a modificare il modo di scegliere le mosse.
Purtroppo per farlo servono milioni di tentativi (partite) e questo significa accumulare milioni di sconfitte, prima di aver imparato qualcosa.
Dove sono questi milioni di partite perse ?
Inoltre, un algoritmo che “impara” deve poi modificare le sue valutazioni in base ai nuovi dati immagazzinati, il che assomiglia molto al continuo lavoro di affinamento che già fanno ( gli umani ) ad esempio su SF.
Se l’uovo di Colombo sta nel fatto che questa operazione la fa molto più velocemente la macchina stessa ( e allora non è una scoperta epocale ) vuoldire che il meccanismo funziona solo per la piccola quantità di “esperienze” già fatte, mentre può essere catastrofico per quanto di nuovo può accadere.
Non credo proprio che abbiano esaurito i casi possibili. Credo piuttosto che abbiano fatto mulinare un set ripetitivo e limitato di aperture.
Viceversa, i miglioramenti di SF sono reali solo quando risultano vantaggiosi per una parte dei casi e più o meno conservativi su tutto il resto.
12 dicembre 2017 - 15:22
Ho letto molti articoli in proposito questi giorni. Alcune considerazioni.
1. Come è stato fatto notare da più parti, il risultato è così clamoroso perché Stockfish è stato malignamente limitato: troppo poca ram e soprattutto tempo di riflessione fisso a un minuto a mossa (che evidentemente privilegia chi cerca meno linee per secondo ma qualitativamente migliori). È chiaro che hanno fatto prove anche con altre cadenze, e questa era quella che favoriva maggiormente il loro sistema.
A prova della loro malafede, il fatto che alcune mosse decisive Stockfish presente sui nostri pc le veda, mentre non le abbia giocate in partita.
2. Detto questo, è impressionante che in sole 4 ore una rete neurale riesca ad arrivare al livello di Stockfish. Meno impressionante se si vede il numero di partite giocate in quelle ore: 700.000!
3. Ciò che estremamente interessante (ed entusiasmante!) è il modo di giocare di AlphaZero. Un modo che ha sviluppato tutto da solo, senza alcuna influenza (e teoria) umana. E si vede!
Bellissimo, come è stato fatto notare, che abbia riscoperto le aperture (andate a vedere gli interessantissimi grafici sull’utilizzo delle varie aperture man mano che la forza del motore aumenta; ricerche di questo tipo influenzeranno clamorosamente la teoria delle aperture nei prossimi anni).
Ma ancora più meraviglioso è che AlphaZero non dà *alcuna importanza* al materiale. L’unica cosa che conta è l’attività dei pezzi. Se ci pensate è logico: un pezzo inattivo, chiuso dai propri compagni, è come se non esistesse! In diversi esempi Stockfish si trova con una superiorità materiale impressionante, ma in una posizione completamente persa. Non credo che questo tipo di gioco possa essere copiato in toto dagli esseri umani: perché necessita un gioco preciso al millimetro, anche una piccola imprecisione può portarti alla disfatta. Per questo, tutto ciò che riguarda la quantità e il valore dei pezzi sarà ancora (sempre?) molto importante nelle partite tra umani; essere in vantaggio materiale ti consente di fare mosse subottimali, senza troppo stress per la ricerca della mossa perfetta.
State sicuri però che le prossime versioni dei migliori software scacchistici saranno calibrate per dare molta più importanza all’attività dei pezzi, a discapito della loro quantità e del loro valore. E dunque AlphaZero impatterà profondamente anche sul loro mondo.
Io ho trovato emozionante il modo in cui AlphaZero utilizzi a volte i propri pezzi esclusivamente per bloccare o rendere inutili i pezzi avversari. Non è importante se sia un alfiere, una torre o una regina: piazza il suo pezzo lì, come se fosse un pedone qualsiasi, e la posizione avversaria diventa irrimediabilmente passiva.
È un qualcosa che assomiglia terribilmente all’umano =).
19 febbraio 2018 - 17:52
Intervento interessante il tuo, ma vorrei fare qualche precisazione…
Lo scopo di una intelligenza artificiale è…
…adempiere al compito per cui è stata creata!
Detta così pare banale, ma nonostante il suo gioco “umano” (chiamiamolo così per differenziarlo da quello di Stockfish), sia interessante per molti aspetti, se non batte sttockfish è inutile…
E’ solo un motore di buon livello come ce ne stanno tanti in giro ormai
Certo giocare in un modo curioso, che non è ne umano, nè tipicamente quello di un motore dà sicuramente benefici al mondo degli scacchi, ma se non batte stockfish resta pur sempre un esperimento sostanzialmente fallito, perchè fallisce nello scopo finale…
Ora…
batte veramente stockfish ?
Qui viene il dubbio: se veramente fa mosse che nemmeno stockfish 5 avrebbe fatto come dice Franco77…
tra le due versione c’è un abisso, penso che pure la 8 batte la 5 con margine molto largo…
Sembra più una pubblicità fatta da Google…
Vorrei vedere un AlphaZero contro uno Stockfish 8 (adesso siamo alla 9) su un normale pc a giocare nelle stesse condizioni
12 dicembre 2017 - 20:43
Si può scaricare questo programma? Gratis o a pagamento?
12 dicembre 2017 - 20:46
Nell’articolo si sostiene che AlphaZero ha giocato contro Stockfish durante l’apprendimento. Invece in questa fase ha effettuato partite solo contro se stesso sfruttando l’enorme capacità di elaborazione dei computer di Google. Questo per regolare i pesi della rete neurale. Una volta “addestrata”, la rete ha affrontato un avversario esterno per valutarne la forza di gioco.
12 dicembre 2017 - 21:17
A maggior ragione. Se la macchina è stata addestrata contro se stessa, può finire facilmente in alcuni “imbuti” che non consentono soluzione. Qualunque coefficiente venga modificato in quella situazione ( ottimizzata, ma specifica, cioè unica ), il risultato peggiora, quindi la macchina dovrebbe imparare da sola a….non entrare in quell’imbuto !
A me questo esperimento sembra molto polarizzato verso il risultato che si desiderava, e immagino che tra non molto scopriremo a cosa si voleva far pubblicità ?
12 dicembre 2017 - 22:18
Durante l’apprendimento la rete viene modificata ad ogni ciclo in modo da aumentare la probabilità di vittoria, cioè avvicinarsi al risultato atteso. Non può peggiorare in nessun caso, perché lo scopo della procedura è la convergenza verso il minimo assoluto della funzione d’errore.
Non è importante contro chi gioco perché la scelta della mossa migliore è puramente statistico. Il metodo Montecarlo è semplice ma formidabile. Scelgo casualmente una mossa e gioco 1000 partite casuali con questa. Scelgo un’altra mossa e gioco 1000 partite con quest’altra. Tra le due, la mossa migliore è quella che mi ha permesso di vincete più partite.
12 dicembre 2017 - 23:52
Allora qualcuno mi deve giustificare perché si chiama “autoapprendimento” quando invece si tratta di giocare tutte le mosse possibili e vedere cosa succede, registrando i risultati e riaggiustando i coefficienti di valutazione.
Da come scrivi, durante l’apprendimento la Montecarlo sceglie casualmente le mosse, ma se il procedimento viene ripetuto un numero congruo di volte, prima o poi ( qualche secolo ) le avrà giocate tutte !
Quindi l’apprendimento si chiama brute force esattamente come quella che conosciamo.
E se si ha abbastanza tempo per apprendere, alla fine si sa tutto!
Se non avessero limiti di tempo e di memoria, SF e company farebbero lo stesso, e potendo registrare i risultati arriverebbero a compilare le tablebases da 32 pezzi.
E se un qualsiasi motore avesse a disposizione le TB32 non avrebbe più bisogno nemmeno di valutare la posizione, basterebbe consultare il database.
13 dicembre 2017 - 00:43
Beh, “qualche secolo” è un po’ riduttivo. Servirebbero milardi di miliardi di miliardi di miliardi di (mi fermo qui per decenza). E anche se si riuscisse a iterare tutte le partite, resterebbe da risolvere un problemino: l’Universo non contiene abbastanza materia per stipare l’informazione necessaria per memorizzare tablebase a 32 pezzi.
Resta quindi il problema generale: come otterere informazioni utili analizzando un numero infinitesimo di posizioni e come memorizzare quell’infinitesimo di informazione in maniera proficua? Finora l’unica risposta era di assegnare un valore alla posizioni (più i due margini di errore nel sistema alpha-beta) e scegliere le continuazioni più promettenti su questa base. Ma per scegliere queste continuazioni, e per valutare la posizione finale, si usano criteri scelti da umani, e umani esperti.
La grande novità della rete neurale consiste nel fatto che i criteri sono lentamente creati in automatico: non servono più umani esperti, la macchina può passare dagli scacchi al Go al Forza 4 senza bisogno che qualcuno le inculchi conoscenze specifiche a parte le regole. Siccome ignora i criteri di valutazione, la rete neurale non può fare altro che scegliere quelli, e le relative continuazioni, a caso, ma il fatto che, risultato dopo risultato, i criteri vengano adeguati e le continuazioni evolvano pertanto in un campione sempre più significativo del mitico “gioco corretto”, è ciò che distingue l’autoapprendimento dalla forza buta e dall’alpha-beta così come implementato su tutti i motori d’élite odierni.
Peraltro, un motore classico potrebbe anche usare l’autoapprendimento per migliorare alcuni parametri (alcuni software anzi lo fanno), ma rispetto alla classica funzione di valutazione una rete neurale offre moltissime più variabili su cui lavorare, e quindi anche i margini di miglioramento non sono paragonabili.
13 dicembre 2017 - 00:29
Complimenti all’autore dell’articolo, sia per i contenuti che per la presentazione, e grazie alla Redazione per averlo proposto anche ai lettori di questo blog.
Credo che la speranza di molti sia che Google diffonda a breve ulteriori informazioni sulla sfida. Uno degli autori ha suggerito che sarà pubblicato un articolo più esteso sul match, che includerà ulteriori partite. Certo, ben altro sarebbe l’impatto se la macchina, o addirittura il sorgente del programma, fossero resi disponibili al pubblico.
Sarà interessante vedere se, e in quanto tempo, le tecniche usate da DeepMind si trasferiranno ai software commerciali. E non penso solo agli scacchi: una rete neurale versatile, messa in commercio insieme ad hardware abbastanza potente per addestrarla, potrebbe forse aprire un’intero nuovo mercato, quasi come i primi mainframe IBM per aziende private avviarono il processo che portò decenni dopo, al PC.
13 dicembre 2017 - 01:02
Per quello che credo di aver capito…
AlphaZero apprende da sé, cioè senza alcun input umano che non siano le semplici regole del gioco: come a dire che non ha i “pregiudizi” forniti dall’uomo, ossia quei principi astratti – falange pedonale, avamposto, case deboli/forti ecc.
Astraendo da questi “pregiudizi” interessante era (ed è) vedere se la macchina svolge o meno una sorta di “rivoluzione copernicana” scacchistica, ossia se rinnova il gioco per come lo intendiamo nei sui principi cardine. Per ora, invece, pare che – e ciò testimonia piuttosto il valore dell’evoluzione umana – CONFERMI la validità del nostro attuale modo di intendere gli scacchi; non è un caso che, in fase di apprendimento, in apertura, abbia seguito la filogensi umana: inizialmente e4-e5, con magari il gambetto di re; per arrivare alle partite di donna e al gambetto di donna. Dunque, al momento, non c’è stata nessuna rivoluzione copernicana.
Resta da capire come se e come la macchina, per come opera, possa cambiare il modo di APPROCCIARE il gioco da parte dell’essere umano. Ora, sappiamo che AlphaZero sceglie le mosse non sulla base di principi astratti (i pregiudizi di cui parlavo pocanzi) ma, se non ho capito male, sulla base di una sorta di calcolo delle probabilità (di vittoria) che ciascuna posizione ottenibile gli fornisce; questo valore lo ottiene giocando una quantità immensa di partite, e dunque di posizioni, e tenendo in memoria tutto questo! In altre parole AlphaZero non solo prescinde da certi principi generali forniti dall’uomo, ma neppure li formula! Dunque, la domanda da porsi è: si tratta di un modo di operare imitabile per un essere umano? La risposta è chiaramente “no”, perché la memoria umana non potrà mai raggiungere quella di un’AI; ed è per questo che l’uomo necessita di princi astratti! Principi che poi andrà ad applicare, di volta in volta, in base alla propria intelligenza.
In altre parole pensare di poter “funzionare” come AlphaZero – e quindi di poterlo utilizzare proficuamente in modo diverso da come si fa con una qualunque engine – è come pensare di poter giocare a scacchi, raggiungendo livelli molto alti, prescindendo dai manuali (che forniscono le regole astratte e generali) e mandando semplicemente a memoria tutte le possibili partite e posizioni esperite durante il gioco.
L’uomo avrà sempre bisogno di regole astratte, ma AlphaZero non opera in questo modo, non “ragiona”, cioè PRESCINDE DALLE REGOLE ASTRATTE, usa memoria e memoria della percentuale di vittoria.
13 dicembre 2017 - 01:14
Per fare un esempio iperbolico: se dopo 10 mosse di una linea della Spagnola AlphaZero ritiene opportuno mandare il re a centro scacchiera perché su 100 mila partite giocate, così facendo – cioè astraendo dal principio generale che vuole il re nelle retrovie al sicuro – ne vince 60 mila; se agisce così, l’essere umano potrai mai seguire il suo esempio? Ossia potrò mai astrarre dal principio generale se, per poter “operare” diversamente, ho bisogno di mandare a memoria 100 mila partite? Ovviamente no, l’uomo avrà sempre bisogno di regole astratte per poter agire, tanto a scacchi quanto nella vita di tutti i giorni. Dunque l’uomo non potrà seguire il suggerimento di una macchina che opera secondo leggi totalmente altre rispetto a quelle dalle quali il cervello umano non può astrarre. Io la vedo così
13 dicembre 2017 - 01:27
Quello che mi ostino a non capire ? in realta è questo: se per imparare gioca un numero immenso di partite, nel breve termine avrà imparato poco, quindi non sarà molto forte, nel lungo termine invece imparerà moltissimo…..fino a sapere tutto, e questo accadrà quando le avrà giocate tutte!
Giocarle tutte per decidere cosa e meglio giocare, significa imparare dai risultati, senza alcuna strategia, quindi è forza bruta, o no ?? ?
In pratica vogliono dire che questo è un sistema più efficiente per implementare la brute force, perchè agendo a caso si impara più velocemente che agendo in base ad una strategia ( e bisogna elaborarne una valida ).
13 dicembre 2017 - 08:15
MM, ma sei de coccio! 🙂
Stock è il prodotto di decadi di conoscenza scacchistica umana “tradotta” in linguaggio macchina. Il pedone vale 1, il cavallo e l’alfiere 3 (con tutti i casi possibili in cui l’uno è più forte dell’altro e viceversa), falange pedonale, avamposto, case deboli/forti ecc. come scriveva franco qua sopra.
In 20 anni siamo passati da un monolito da milioni di dollari capace solo di giocare a scacchi “abbastanza bene” da battere Kasparov ad app per smartphone che possono battere Carlsen seguendo questo sistema.
Alpha non ha nulla di tutto questo: a quanto ci viene detto ha solo le regole che trovi nei foglietti delle scacchiere cinesi 😀
Non si infila in imbuti (o se ci si infila, ne esce) perché non ha algoritmi che ce lo fanno finire.
Non ho competenze informatiche sufficienti per discutere di cosa sia la forza bruta rispetto all'”intelligenza”, ma non posso non togliermi il cappello di fronte a qualcosa che qualsiasi cosa faccia e come la faccia la fa da solo mentre noi guardiamo e basta. E che se glielo chiediamo la fa anche contro il miglior goista.
(si parla, in prospettiva, di mercati finanziari e cure per il cancro, ok suona una sparata bella grossa)
13 dicembre 2017 - 10:48
In vicende come questa sono più che di coccio, sono di acciaio al manganese.
Il nocciolo della questione si chiama “retropropagazione” che poi sarebbe la vera novità di questi sistemi, e consiste nel redistribuire a ritroso il dato ottenuto, in modo che il risultato finale precedente possa essere migliorato modificando i parametri delle celle che lo hanno “trasportato”, quindi facendo il percorso a ritroso ( output/celle intermedie/input ) le suddette celle modificano il modo di operare, in un continuo processo di approssimazioni successive.
Gli imbuti di cui parlavo esistono, perchè una funzione complessa nella quale le variabili sono interdipendenti ( come è negli scacchi ) può raggiungere un risultato che minimizza l’errore ( senza azzerarlo ) ma poi non riesce più a migliorarlo, perchè per ottenere un dato finale migliore dovrebbe paradossalmente transitare ( uscire dall’imbuto ) per un risultato intermedio peggiore.
Questa anomalia è risolta in parte dall’impiego di coefficienti casuali, per cui i parametri non sono modificati uno ad uno secondo una logica, ma vengono modificati insieme ( o a gruppi ) randomicamente, il che consente di uscire dall’imbuto senza arrampicarsi sulle sue pareti scivolose ☺
19 febbraio 2018 - 18:00
Si ok….
Tutte belle cose e tante belle promesse di effetti speciali e colori ultravivaci…
Ma se non batti stockfish restano, appunto, promesse
Sono anni che si provano le reti neurali in tanti campi, anche gli scacchi, senza successo
Alphazero ha vinto, ma sembra a condizioni molto svantaggiose per stockfish il che fa dubitare molto
della reale forza di Alphazero e di come finirebbe una sfida alle stesse condizioni
Poi ovviamente, la scienza avanza di continuo e prima o poi avremo dei cambi di paradigma effettivi (e non solo promessi), ma ci sono dei dubbi se quel momento sia arrivato ora con Alphazero…
13 dicembre 2017 - 12:02
Mario scrive: “se per imparare gioca un numero immenso di partite, nel breve termine avrà imparato poco, quindi non sarà molto forte, nel lungo termine invece imparerà moltissimo…..fino a sapere tutto, e questo accadrà quando le avrà giocate tutte!”
Ciao Mario, apprezzo sempre molto i tuoi commenti qui su Scacchierando, ma credo tu non abbia capito il punto in questo caso.
Si stima che il numero di possibili partite a scacchi sia di 10.000.000.000^50 (dieci miliardi elevato a 50!).
AlphaZero ha giocato 700.000 partite, cioè lo
0,000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000
0000000000000000000000000000007% delle partite possibili!
QUATTROCENTONOVANTATRE ZERI!
Anche se AlphaZero giocasse 20 o 30 anni da solo non riuscirebbe a raggiungere neanche lo 0,0000000000001% delle partite giocabili.
Quindi è evidente che non si tratta di “giocarle tutte”.
Oltretutto credo che sia sfuggito un po’ a tutti come funzioni una rete neurale. Una rete neurale non immagazzina al suo interno le singole partite (quindi non ha la memoria di ogni singola partita che ha giocato), ma cambia il valore dei propri collegamenti ogni volta che ne gioca una. Per questo si parla di sistema “che apprende”.
Il risultato finale sarà un sistema che si è modellato sulla base dei singoli risultati di ciascuna partita, ma che in memoria non ne ha neanche una di esse.
13 dicembre 2017 - 12:44
Grazie, questo lo sapevo. ☺
Grazie anche per aver digitato gli zeri, che altrimenti non si capiva nulla ?
Il senso di quello che ho scritto, se esiste, sta nel fatto che la macchina che si vuole pubblicizzare compie le stesse operazioni che oggi sono realizzate dall’insieme macchina + programmatore, con l’evidente intento di prescindere dal programmatore, e di farlo piu rapidamente ( non necessariamente meglio, anche se questo non ci dovrebbe interessare, per ora ).
In questo senso tenta di riprodurre il modo di apprendere degli umani: nel nostro caso l’umano da emulare sarebbe un GM in pectore, che inizia a giocare a 6 anni e conosce solo le regole del gioco.
Poi gioca e da ogni partita ricava informazioni utili a modificare il suo comportamento nella partita successiva.
Ovviamente ci sono alcune differenze: se l’umano agisse solo in base al risultato ottenuto, senza studiare la teoria e senza avere una guida autorevole al suo fianco, questo metodo darebbe risultati assai scarsi e comunque dovrebbe passare per una lunga serie di insuccessi.
Quindi il primo punto è che nella fase di apprendimento la macchina è inutilizzabile, accumula insuccessi che servono solo a modificare i coefficienti da assegnare ai suoi neuroni, però alla fine sarebbe in grado di affrontare anche problemi mai esaminati prima ( con risultati da verificare ).
Quanto debba essere lunga la fase di apprendimento è meno importante, d’accordo, perchè in fondo è una macchina, e lo farà più velocemente degli umani.
Il secondo punto è che nella fase di apprendimento la macchina non può essere distratta da tutte le vicende che invece condizionano gli umani, quindi ha un grosso vantaggio di efficienza.
Il terzo punto è il risultato pratico : un sistema simile applicato agli scacchi può raggiungere risultati eclatanti anche contro uno Stockfish non depotenziato, ma è difficile che arrivi nelle nostre case.
Negli altri campi di applicazione immagino ci siano intere praterie da occupare.
13 dicembre 2017 - 09:54
Annimo 109, purtroppo questo Alphazero più si appofondisce più lascia dubbi.
Cito Francesco Massei da IHS:
” a me in realtà erano saltate all’occhio altre
domande forse più correlate con un analisi simile:
– perché giocare solo contro stockfish? Capisco nella fase d’apprendimento,
ma dopo si poteva anche far giocare contro altri engine.
– perché stockfish è stato sempre settato nello stesso modo? Probabilmente
variando i parametri l’apprendimento non funzionava (il che è curiosamente
capibile anche per un uomo: immaginate di essere cresciuti con un padre GM!)
– perché la rete è stata monitorata in una sola configurazione? Anche questo,
forse perché c’hanno messo un po’ a tararla e, come spesso succede, non
volevano spendere altri mesi a cercare di capire il perché per completare
la pubblicazione.
– perché non ci sono i boundaries di scalabilità? 🙁 Questa è forse la cosa
che più fa pensare”
Aggiungo anche la mia considerazione: “Se questi di Alphazero fossero intellettualmente onesti, organizzerebbero un paio di match “seri” contro Komodo o Houdini (i due recenti finalisti TCEC), con impostazioni e tempi di riflessioni congrui, diciamo proprio stile TCEC. POi vediamo i risultati.
Così come è ora, questo alphazero mi sa tanto di (poco) arrosto (magari buonissimo, eh!) e parecchio fumo negli occhi dei non esperti “
13 dicembre 2017 - 10:53
Scusate se mi permetto di intervenire dal basso della mia ignoranza informatica, ma la mia modesta sensazione è che alcune questioni assai dibattute siano di fatto *irrilevanti*.
Si discute di un nuovo software che gioca bene a scacchi e ci si domanda quanto bene giochi davvero, cose che mi sembrano di importanza modestissima.
Non capisco che importanza possa avere se AlphaZero è un 3400 o un 3700 di Elo.
In ogni caso migliora allenandosi, per cui se fosse un 3400 potrebbe arrivare facilmente a 3700 lasciandolo in allenamento ancora qualche ora o al limite qualche giorno.
Mi sembrano discorsi inutili, quelli sulla reale forza di AlphaZero.
Si dibatte se Stockfish sia stato discriminato e si invocano match più equi.
A che pro, mi domando?
Forse non si è compreso che qui non si sta parlando di competizioni sportive, ma di tutt’altro.
Certo che il match costituiva un lancio pubblicitario per Google e certo che Stockfish non è stato messo nelle condizioni per lui ottimali. Nel qual caso – secondo i suoi mentori – quest’ultimo non avrebbe comunque vinto il match, ma avrebbe potuto ottenere molte più patte.
A Google però serviva un risultato ampio da urlare sui giornali e così Stockfish è stato depotenziato in qualche misura.
Marketing? Sì.
Marketing pure un po’ disonest … vabbè, diciamo “ingannevole”? Sì.
Bene, ma ora che ce lo siamo detti mi domando che importanza abbia, su una scala più ampia.
Facciamo così: facciamo che Stockfish, se fatto competere al massimo delle sue possibilità, avrebbe pattato tutte e 100 le partite del match (temo proprio di no, ma come detto la cosa è irrilevante).
Anche così, anche in caso di match pareggiato, avremmo che un software *non* progettato per giocare a scacchi ha ottenuto un risultato mostruoso con poche ore di lavoro in proprio (contro decenni di conoscenze specifiche acquisite dall’altra parte della barricata) e con un metodo che – bello o brutto che sia – è completamente diverso da quelli sino ad oggi utilizzati.
E’ una rivoluzione, a prescindere dalla effettiva forza scacchistica manifestata da AlphaZero il giorno 5 dicembre 2017 (forza scacchistica che – ripeto ancora – è *irrilevante*).
AlphaZero non serve a giocare a scacchi e può benissimo darsi che non ci giocherà mai più.
Google se ne strafrega degli scacchi, ok?
E ancor di più se ne strafrega di Komodo & C.
Il punto sono le applicazioni che può avere in tutti i campi. In realtà l’idea non è neppure nuova: già da anni ci sono software che – sfruttando le loro capacità di pattern recognition, alla base pure del successo di AlphaZero – individuano alcuni tipi di tumore con più precisione dei medici umani.
Non conosco la differenza tra questo e quelli, ma immagino che questo possa essere un ulteriore passo avanti in quella direzione (e in mille altre).
Il match di scacchi è solo una vetrina pubblicitaria e come tale va trattato: stiamo discutendo di una pubblicità natalizia della Coca-Cola con i Babbi Natale, né più né meno.
Ciò detto, c’è poco da dubitare della forza – quanto meno potenziale – dello strumento AlphaZero.
E c’è poco da dubitare che il nuovo approccio, basato più sulla pattern recognition che sul calcolo, costituisca una rivoluzione nel mondo dell’informatica scacchistica.
Diciamo che AlphaZero non era poi così tanto forte in quel momento e che ha vinto “barando”?
Ma se (per assurdo) a Google interessassero gli scacchi e lasciasse AlphaZero ad allanarsi per un mesetto invece che per quattro ore, glielo concediamo che arriverebbe a livelli di gioco piuttosto inquietanti e che Stockfish non costituirebbe un grande ostacolo?
Il punto però è che non è quello il punto.
13 dicembre 2017 - 11:00
Marketing disonesto? oppure truffa bella e buona? Google ha ottenuto la pubblicità che cercava, ma a ben vedere non si è ancora capito come funzioni il suo “miracolo tecnologico”, e l’unica cosa che possono portare come prova di funzionamento puzza di tarocco,
Oppure , caro Edo, tu ti fideresti ad acquistare un’automobile spacciata come “completamente auto guidante” ma il cui test è stato fatto solo su una autostrada a sei corsie chiusa al traffico?
13 dicembre 2017 - 11:10
Ho scritto tanto, probabilmente troppo.
Evidentemente senza riuscire a spiegarmi.
13 dicembre 2017 - 11:02
lordste, MM,
rimando a quanto detto da Edo, ha detto tutto quello che penso, molto meglio di come lo avrei fatto io 😀
13 dicembre 2017 - 11:49
Accade spesso ?
Scherzi a parte, concordo che la questione sia molto più ampia e importante del solo giocare a scacchi.
Troppo spesso la prima cosa che noto in ogni attività umana è il tentativo di ricavare un qualche vantaggio ( perlopiù economico, ma può essere altro ) nel proprio campo, con mezzi apparentemente innocui, che però alla lunga si scoprono essere tutt’altro.
Siccome il mezzo ( o metodo ) utilizzato è buon indizio del fine ultimo che si vuole ottenere, per me è importante farsi una idea di come sono stati ottenuti i risultati che si vogliono divulgare.
13 dicembre 2017 - 12:28
ma il punto non è se AZ raggiunga o meno una forza di molto superiore a qualsiasi engine concepita in modo tradizionale (come Stoccafisso, per intenderci). il punto è che AZ non ti dice, in una data posizione raggiunta, “qui il vantaggio è X (per es. +5 centipedoni)” come fanno le engine che conosciamo; questo non è un valore che AZ calcola. per AZ una posizione è migliore di un’altra se, in percentuale sulle migliaia (o sui milioni) di identiche posizioni esperite da lui in passato, fornisce una più alta probabilità di vittoria. cioè di portare al matto!
Ma un essere umano potrà mai avvalersi dei consigli di una macchina che ragiona in questo modo? Come dicevo, posso entrare in una qualsiasi posizione consigliatami sulla base del principio che ha alte probabilità di condurre al matto – magari dopo altre 50 mosse – e ignorando il vantaggio in centipedoni che possiedo (cioè ragionando secondo il modo di “ragionare” di AZ) solo se ho al contempo la capacità di ricordare tutte le probabilità di vittoria di ciascun ramo dell’albero che ramificherà da quella posizione specifica (che è quello che riesce a fare AZ). Cosa che un umano non può fare!
13 dicembre 2017 - 12:37
in altre parole è assurdo pensare che una forma di intelligenza possa istruirci e formarci se il suo paradigma epistemico è totalmente altro rispetto al nostro e, soprattutto, è paradigma che il nostro cervello non può impiegare in modo più proficuo rispetto a quello che già possiede
13 dicembre 2017 - 12:52
la rivoluzione in ambito scacchistico, di cui molti parlano, non potrà avvenire perché l’essere umano non può funzionare per pattern recognition – che è, in parole povere, un modo più evoluto di “andare a memoria”. Ed anzi, si tratta esattamente del primo monito che viene dato a tutti i principianti: “non andare a memoria, ragiona anzitutto per principi!”, e questo già semplicemente in fase di apertura, figuriamoci se è possibile farlo alla 50esima mossa di una delle 2000 possibili varianti di una qualsiasi partita. Anche qualora AZ mi dicesse che alla 50esima mossa di una data partita la mossa migliore è X io, dopo averla scelta, dovrei essere in grado di proseguire autonomamente, cosa che non posso fare perché non mi vengono fornite altre informazioni che non il semplice fatto che quella mossa ha le maggiori possibilità di condurre al matto (da lì ad altre 50 mosse, magari): quel consiglio diventerebbe proficuo, per me, solo se poi avessi la capacità di discriminare tutte le possibili ramificazioni successive sempre sulla base della probabilità di portare al matto; cosa che, come essere umano, non sono in grado di fare
13 dicembre 2017 - 14:05
Se le ipotesi di Edo sono giuste, e non ne dubito, gli scacchi sono stati utilizzati come “esca” pubblicitaria, in quanto chi sa giocare bene a scacchi è comunemente indiziato di essere più intelligente della media ( falso, al più è meglio attrezzato per usare la sua intelligenza in quel campo specifico ).
Allora battere Stockfish serve solo ad accendere i riflettori, creare una “falsa traccia”, mentre lo scopo è attirare l’attenzione ( fondi oppure, più in là, potenziali clienti ) sui risultati ottenibili con una macchina così congeniata.
Ovvio che nessuno pensava di creare un istruttore di scacchi.
Un elemento che mi sovviene adesso riguarda invece la possibilità di capire come si è “autostrutturata” la macchina al termine della fase di apprendimento, in modo da soppesare la rilevanza dei vari elementi nel suo processo decisionale.
Sarebbe molto utile ma, se ho capito bene, alla fine dell’apprendimento non si può ricostruire il percorso compiuto dalla macchina, bensì solo registrare il suo stato finale.
13 dicembre 2017 - 14:23
ah certo, ma basta avere consapevolezza di come stano le cose e va bene tutto, sono d’accordo. se si tratta di un mero “spot promozionale” basta capire che di quello si tratta e non scambiarlo per qualcosa che potrà rivoluzionare il nostro modo di intendere e giocare gli scacchi. perché sullo scovare tumori può senz’altro essere un’ottimo strumento, ma nel campo degli scacchi.. beh, al tavolo da gioco devo sedere comunque io, mica posso mandarci AlphaZero, e quindi o posso ragionare come fa lui o mi serve a poco
13 dicembre 2017 - 15:22
https://medium.com/@josecamachocollados/is-alphazero-really-a-scientific-breakthrough-in-ai-bf66ae1c84f2
13 dicembre 2017 - 15:34
Come potete leggere dall’articolo che ho linkato, l’autore (Maestro internazionale E esperto di Intelligenza Artificiale) solleva più di un dubbio sulla questione… buona lettura.
13 dicembre 2017 - 15:44
Ho letto. Devo dire che la vedo più o meno come Camacho Collados: scientificamente (inteso, come procedimento prima e divulgazione poi) si poteva senz’altro fare meglio, fatto salvo resta qualcosa con grosso potenziale.
Ma si deve risottolineare che un 28 a 0 in queste condizioni o 14 a 14 in altre o qualsiasi altro risultato in altre ancora ha importanza estremamente relativa: noialtri scacchisti siamo “la coca-cola di natale”, il punto è altro*.
Grazie del link!
* a meno, ovviamente, di pensare che il suo valore scacchistico reale sia intorno ai 1500 Elo e che il tutto sia pura e semplice truffa 😀
13 dicembre 2017 - 17:22
* a meno, ovviamente, di pensare che il suo valore scacchistico reale sia intorno ai 1500 Elo e che il tutto sia pura e semplice truffa <—-
Sai com'è, man man se ne parla saltano fuori talmente tante "gabole" che comincia a venirmi il sospetto che possa essere così (oddio magari 1500 no ma le sconfitte pubblicate di SF sembrano parecchio "strane" e incomprensibili per un motore che anche da zoppo come l'han fatto giocare dovrebbe tenere i 3000)
13 dicembre 2017 - 18:04
Nuova era o bluff, probabilmente siamo nel mezzo, ma qui possiamo sviscerare con una certa competenza solo gli aspetti legati agli scacchi, quindi, irrilevante o no, parliamo del test che ha coinvolto la controfigura di SF.
Ho visto rapidamente solo due delle 10 partite scelte dal team “non-del-tutto-imparziale” di AlphaZero per veicolare il loro grido di gioia e devo dire che per la maggior parte delle mosse il mostro sembra umano, nel senso più ampio, quindi comprese quelle che a prima vista sembrano errori ( ho visto un nero con alfiere in d6 che teneva i pedoni c7/e5, e nel seguito Alpha ha spinto anche f6 c5 f4, lasciandogli solo una piccola speranza di non morire da pedone, sfruttata poi 20 mosse dopo con la manovra Ad6-f8-h6- e infine Axe3 dopo aver aperto la diagonale ).
Quello che non si capisce nemmeno alla lunga è invece il gioco di Stockfish, ma non sono riuscito a scaricare il pgn delle 10 partite ( solo per i Premium ) quindi sospendo il parere sulla eventuale taroccatura del match.
13 dicembre 2017 - 18:16
Suppongo che a Google sia pure andata male.
Credo che le intese fossero anteriori al mondiale TCEC.
E diciamolo, sicuramente speravano di creare un clamore maggiore… “il nostro ha vinto contro il campione del mondo…”.
Per i soldi di Google si darebbero a perdere anche i campioni?
13 dicembre 2017 - 18:31
Mano a mano che leggo qualcosa si aggiungono dettagli non secondari.
La macchina AlphaZero è derivata da quella che aveva imparato il Go, ma mentre questa aveva imparato “da sola”, quella destinata agli scacchi ha ricevuto in dono dei parametri iniziali ( yperparameters, credo, servono a risparmiare tempo in modo che la macchina trovi già pronti quelli ottimali per il problema a cui viene destinata ).
Inoltre le 4 ore di apprendimento, che sembrano poche, non lo sono più se vengono impiegate da 5000 TPU coordinate da 19 server, come dire da un supercomputer di nuova generazione.
La macchina singola costa più o meno 25 milioni di euro, quindi chi sorveglia sul cheating può stare tranquillo, per ora. ?
13 dicembre 2017 - 18:50
Io trovo interessante il fatto che diversamente da come sembrava inizialmente il “coso” ha effettivamente giocato contro Stock durante “l’apprendimento”: si vira così effettivamente da “istruzioni da scacchiera cinese” verso “papà GM” 🙂
(questa e altre “magagne” su https://en.chessbase.com/post/alpha-zero-comparing-orang-utans-and-apples )
13 dicembre 2017 - 20:53
Editate il commento con gli 0 per favore che rende la pagina illeggibile in mobile. Detto questo
https://www.technologyreview.com/s/609736/alpha-zeros-alien-chess-shows-the-power-and-the-peculiarity-of-ai/
13 dicembre 2017 - 21:04
Grazie, spero di aver risolto.
16 dicembre 2017 - 00:20
Cosa ne pensano all’Est ?
http://chesspro.ru/guestnew/looknullmessage/?themeid=54&id=69&page=0#54-69-6236
16 dicembre 2017 - 23:00
Premesso che le mie competenze di informatica si estendono alla capacità di fare click con il mouse, nel frattempo una rete neurale di Google ha scoperto, analizzando una piccola parte dei dati del telescopio spaziale Kepler, due esopianeti. Messo a punto il sistema credo che gli esopianeti potrebbero grandinare (dalla piccola porzione di spazio osservata da Kepler) visto che la mole di dati ancora da analizzare è enorme.
E’ probabile che Google abbia cercato una buona pubblicità attraverso gli scacchi e sarebbe stato interessante verificarlo al mondiale dei software, ma mettendoci anche il Go, la sensazione è che il potenziale delle reti neurali sia enorme. Si perdono ancora in un bicchiere d’acqua, come ho letto, ma…
7 gennaio 2018 - 17:05
Probabilmente Stokfisch non era tarato al meglio delle sue possibilità, probabilmente lo avranno forzato a muovere in poco tempo a mossa, probabilmente l,autoapprendimento di Alphazero sarà stato eseguito su un milione di processori, diventando così quattro milioni di ore!
Lascia un commento
Devi essere loggato per lasciare un commento. Clicca per Registrati.
Clutch Chess: Champions Showdown
"Una tradizione iniziata da...
Clutch Chess: Champions Showdown
Carlsen in beast mode nel giorno...
Surfing on the Net – Ottobre 2025
Tabatabaei e Fedorchuk se la...
Campionato Europeo Giovanile 2025
Ho fatto una foto alla sala di...
Campionato Europeo Giovanile 2025
Sul sito ufficiale l'orario...
Campionato Europeo Giovanile 2025
Grazie Danyyil, ho corretto...
Campionato Europeo Giovanile 2025
Buongiorno, consiglierei di...
Clutch Chess: Champions Showdown
Beh! "Come cambiano in fretta le...
Surfing on the Net – Ottobre 2025
Prraneeth Vuppala ferma Tabatabaei...
Clutch Chess: Champions Showdown
Giornata da dimenticare per...
Fa un certo effetto ritrovarci qui in Surfing per...
Terza edizione e terzo continente diverso per i...
Fabrizio Bellia parte da numero 15 del...
Il Kazakistan offre nuovamente un evento...